Google Tests AI Headline Rewriting as Publishers Launch Four Collective Licensing Initiatives
Google is testing AI-generated headline and title replacements in search results, overriding publisher-defined metadata. Simultaneously, four major collective licensing initiatives have emerged: the SPUR coalition (FT, Guardian, Telegraph, BBC, Sky News) to prevent unauthorised AI scraping; Publishers' Licensing Services' 'Generative AI Solution' for UK publishers; IAB Tech Lab's Content Monetisation Protocol; and the NMA–Bria attribution-based revenue-share model. Chartbeat data shows a 60% decline in referral traffic for small publishers. AI platforms currently contribute less than 1% of total publisher pageviews.
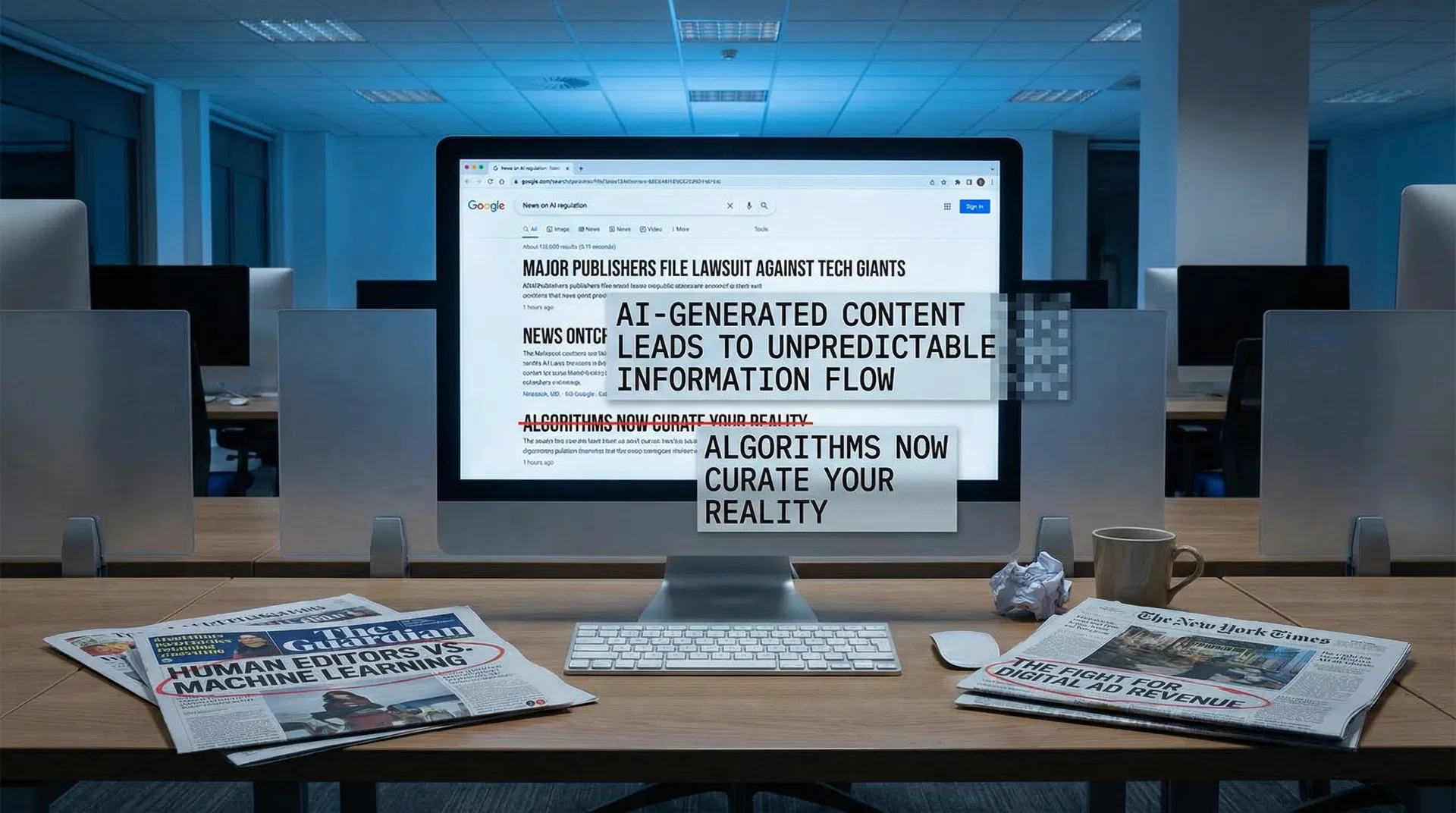
Analysis
The two developments covered in What's New in Publishing's March 26 analysis — Google's AI headline rewriting and the emergence of four parallel collective licensing initiatives — are more closely connected than they might appear, and understanding the connection is essential for publishers trying to navigate the current moment.
Google's decision to test AI-generated headline replacements in search results is, on its surface, an editorial intervention: the search engine is deciding that its AI-generated description of a publisher's content is more useful to searchers than the headline the publisher wrote. This is a significant escalation of Google's existing practice of rewriting page titles in search results, which has been a source of publisher frustration since 2021. The difference is that AI-generated rewrites are not merely cosmetic — they can fundamentally alter the framing, tone, and emphasis of a story in ways that affect click-through rates, brand perception, and the publisher's ability to control its own editorial voice.
The practical implications are significant. A publisher who writes a headline designed to attract a specific audience — "Why Independent Bookshops Are Thriving Despite Amazon" — may find that Google's AI rewrites it as "Independent Bookshops vs Amazon: The Competition Continues," stripping the editorial perspective that made the original headline distinctive. At scale, this erodes the differentiation between publishers and commoditises their content in exactly the way that the collective licensing initiatives are trying to prevent.
The four licensing initiatives represent the industry's most coordinated response yet to the AI content challenge, and their simultaneous emergence is not coincidental. SPUR's technical approach — preventing unauthorised scraping — addresses the supply side of the problem. PLS's collective licensing scheme addresses the commercial side, creating a mechanism for publishers to be paid for content that AI companies are already using. IAB Tech Lab's Content Monetisation Protocol addresses the standards side, creating a common technical language for AI permissions. The NMA–Bria model addresses the small publisher access problem, aggregating 2,200 members into a single licensed pool.
The fact that four separate initiatives have emerged rather than one reflects the fragmented nature of the publishing industry and the absence of a single body with the authority to negotiate on behalf of all publishers. This fragmentation is both a weakness — it reduces negotiating leverage — and a strength — it creates multiple experimental models that can be evaluated and refined. The PLS model (collective licensing with opt-in) and the NMA–Bria model (attribution-based revenue share) are structurally different enough that the industry will learn something useful from whichever performs better over the next two years.